Writing
The DAACS system can automatically score written responses from students. It uses the Lightside models to do the scoring.
Training DataWhen creating a CSV file to use with Lightside, it must contain two columns namedScoreandtextotherwise DAACS will not work.
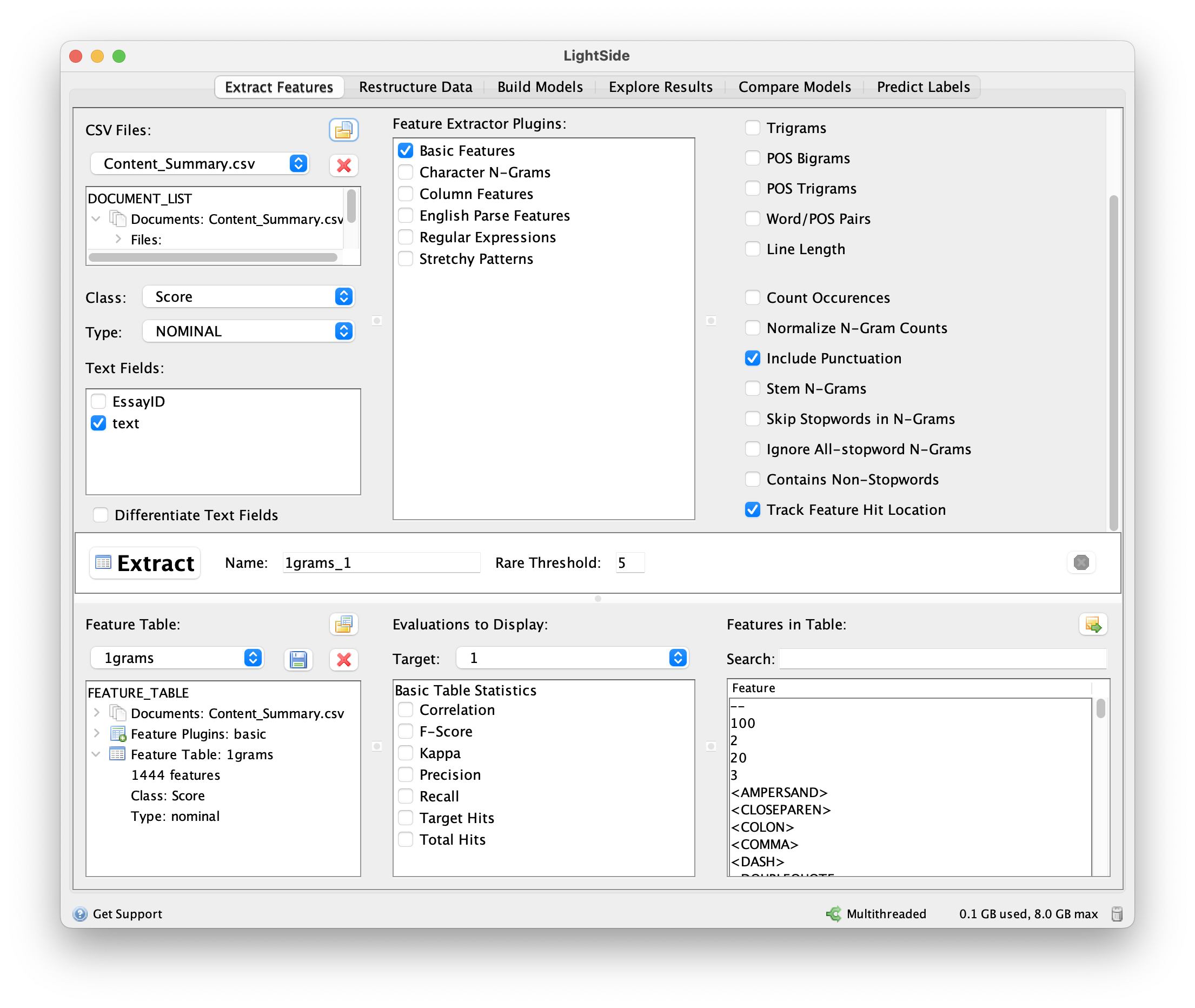
When you first open Lightside, you will be presented with the screen below to load your data file (in CSV format) and to select what features you want extract. Be sure select NOMINAL for the score type and select text under text fields. The Lightside documentation provides details about each of the feature extraction options. Choosing the correct combination is a combination of theory (i.e. picking the features that are related to the criteria) and trial-and-error to obtain the highest accuracy. The table below provides details about which features were used for each criteria for our rubric.
Once the features are extracted we move to the “Build Models” tab. Here, we will train a machine learning algorithm to predict the score from the extracted features. By default Lightside uses 10-fold validation to estimate fit statistics. The bottom middle provides the accuracy and Kappa and the lower right the full confusion matrix. A typical workflow involves checking the accuracy, returning to the “Extract Features” tab and change options, retrain the model, compare the accuracy, and repeat. Ideally you would have a separate validation dataset with which you would estimate fit statistics (e.g. accuracy, Kappa) against your final feature and model combination to report final estimates.
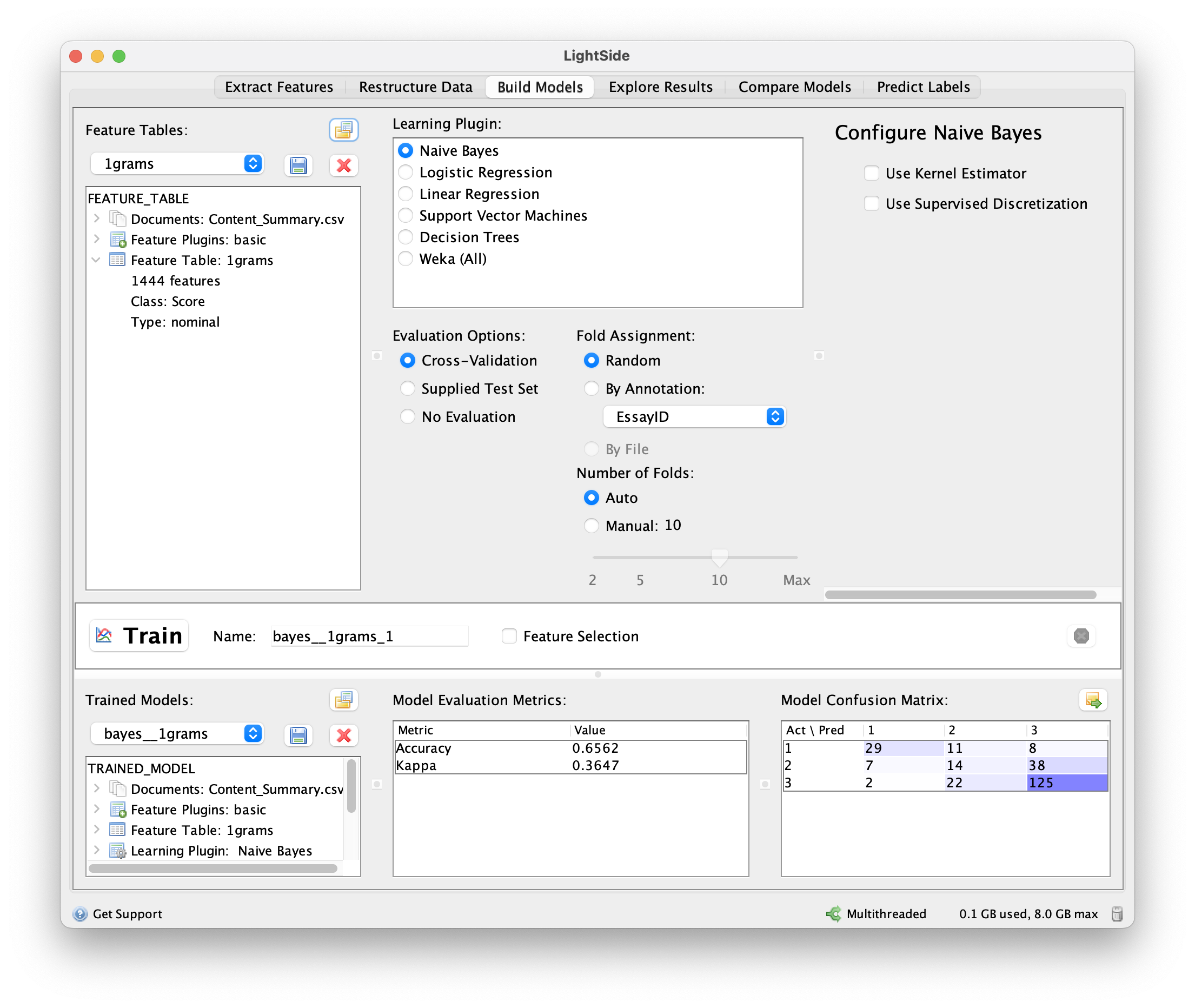
Once you have decided on a final model, you can save the model using the save icon in the lower left side. The file saved is what you will upload to DAACS to conduct the machine scoring.
Prediction FileThe model file may be very large. It is stored in XML format which can be opened in any text editor. The file is large because it contains a full copy of the training data which is not necessary for predictions. You can delete that data to reduce the file size.
Lightside Models and Features by Criterion
| Summary | Suggestions | Structure | Transition | Focus | Cohesion | Correct | Complex | Conventions | |
|---|---|---|---|---|---|---|---|---|---|
| Model | Logit | Logit | Bayes | Bayes | Logit | Logit | Logit | Bayes | Logit |
| Accuracy | 69.92 | 72.26 | 74.22 | 47.17 | 73.45 | 72.73 | 55.73 | 68.42 | 63.16 |
| % Bad error/nonadjacent | 0.05 | 0.06 | 0.01 | 0.04 | 0.12 | 0.01 | 0.07 | 0.003 | 0.04 |
| Unigrams | X | X | X | X | X | X | X | X | X |
| Bigrams | X | X | X | ||||||
| Trigrams | X | X | |||||||
| POS Bigrams | X | X | X | ||||||
| POS Trigrams | X | X | X | ||||||
| Word/POS Pairs | X | X | X | X | X | X | X | X | X |
| Line length | X | X | X | X | X | X | X | X | |
| Count occurences | |||||||||
| Normalize N-gram counts | |||||||||
| Include punctuation | X | X | X | X | X | X | X | X | X |
| Step N-grams | X | ||||||||
| Skip stopwords | |||||||||
| Ignore all stopwords | |||||||||
| Contains non-stop words | |||||||||
| Character N-grams | X | X | X | X | X | ||||
| Stretchy patterns | X | X | X | X | X | X |